Миграция установленного Linux’а на другую машину
Содержание
Перенос Linux’а на другой компьютер
Причин для переноса установленного Linux’а на другой компьютер или виртуальную машину может быть множество. У меня причина простая, я наигрался с CentOS’ом в Parallels Desktop’е на ноутбуке и решил его перенести в виртуальную машину на Mac mini, где у меня запущен VMware ESXi 5.5.
Переносить можно по-разному, можно сделать бэкап какой-нибудь сторонней утилитой, а затем восстановить операционную систему уже на новом месте. Но я выбрал самый простой вариант — перенос содержимого диска по сети используя утилиты dd и NetCat (в случае если будет использоваться незащищённый канал связи, можно использовать вместо netcat’а — ssh, это на порядок медленнее, зато безопаснее).
Порядок действий для переноса:
- Создаём в
VMware ESXiвиртуальную машину с аналогичным размером виртуального диска (под понятие создаём виртуальную машину попадает: создание виртуальной машины, прописывание ей определённогоMAC-адреса, создание статической записи вDHCP-сервере для этогоMAC-адреса и соответствующего емуIP-адреса и назначение имени дляIP-адреса в сервереDNS).
В дефолтном ядре
CentOS 7драйвера дляSCSI-контроллеровLSIиVMware Paravirtualскомпилированы как модули, поэтому если создать виртуальную машину соSCSI-диском – она не загрузится. Так что лучше создаватьIDE-диск. - Скачиваем и загружаем
SystemRescueCDи в виртуальной машине донора, и в виртуальной машине реципиента. - На машине донора подключаем
SystemRescueCDкак виртуальный диск и загружаемся с него (в меню выбирайте самый верхний пункт).
- На предложение выбрать раскладку можно, в принципе, не реагировать, всё равно русский язык нам не понадобится. Но если перфекционизм — ваш конёк, можно ввести
31и нажать«Enter». ?
- После загрузки увидим стандартную
Linux’овую консольку с небольшой инструкцией по настройке сети, а так же с перечнем предустановленных утилит.
- На машине реципиента так же подключаем
SystemRescueCDкак виртуальный диск и загружаемся с него. - На обеих машинах первым делом устанавливаем пароль для
root’а, для того чтобы можно было подключаться к машине используяssh:
1234567root@sysresccd /root % passwdChanging password for rootEnter the new password (minimum of 5 characters)Please use a combination of upper and lower case letters and numbers.New password:Re—enter new password:passwd: password changed. - Для того чтобы отличать одну консоль от другой, изменим строку приглашения
shell’а на обеих машинах. На доноре выполним команду:
1PS1=«(source) $PS1»
а на реципиенте команду:
1PS1=«(target) $PS1» - Теперь проверяем что на нашем доноре работает сеть:
12345678910111213(source) root@sysresccd /root % ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWNlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000link/ether 00:1c:42:bf:1c:1c brd ff:ff:ff:ff:ff:ffinet 192.168.255.130/24 brd 192.168.255.255 scope global eth0valid_lft forever preferred_lft foreverinet6 fe80::21c:42ff:febf:1c1c/64 scope linkvalid_lft forever preferred_lft forever
Если сDHCP-сервером всё хорошо, то вручную настраивать сеть не нужно будет, в противном случае необходимо будет настроить сеть используя следующую команду:
1(source) root@sysresccd /root % net—setup eth0 - Обратите внимание, что сетевой интерфейс не обязательно будет называться
eth0, при загрузкеSystemRescueCDвVMware ESXi, сетевой интерфейс, к примеру, называетсяens160:
12345678910111213(target) root@sysresccd /root % ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWNlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000link/ether 00:50:56:02:02:01 brd ff:ff:ff:ff:ff:ffinet 192.168.255.202/24 brd 192.168.255.255 scope global ens160valid_lft forever preferred_lft foreverinet6 fe80::250:56ff:fe02:201/64 scope linkvalid_lft forever preferred_lft forever - Пароль для
root’а задали, сеть настроили, теперь осталось только проверитьpingс машины на машину и можно приступать к главному, к переносу информации с диска на диск. - Для начала необходимо узнать как в наших системах называются жёсткие диски, для этого выполняем следующую команду на доноре:
123(source) root@sysresccd /root % lsscsi[0:0:0:0] disk ATA CentOS Linux—0 S F.W6 /dev/sda[1:0:0:0] cd/dvd Virtual DVD—ROM R103 /dev/sr0
И аналогичную команду на реципиенте:
123(target) root@sysresccd /root % lsscsi[1:0:0:0] cd/dvd NECVMWar VMware IDE CDR10 1.00 /dev/sr0[2:0:0:0] disk VMware Virtual disk 1.0 /dev/sda
В обоих случаях диск называется /dev/sda, запомним это и приступим к переносу. - Сначала на машине реципиента запустим серверную часть утилиты
NetCat, которая будет записывать на диск всё что получит по сети с другой машины:
1(target) root@sysresccd /root % nc —l —p 19000 | dd bs=16M of=/dev/sda<!— [Format Time: 0 plavix 75 mg.0011 seconds] —>
- Теперь на машине донора запусти клиентскую часть утилиты
NetCat, которая будет считывать данные с исходного диска и передавать по сети на другую машину:
1(source) root@sysresccd /root % dd bs=16M if=/dev/sda | nc centos2.acmelabs.spb.ru 19000 - Выше описан вполне рабочий вариант, но его можно улучшить добавив сжатие на лету:
12(target) root@sysresccd /root % nc —l —p 19000 | gzip —c | dd bs=16M of=/dev/sda(source) root@sysresccd /root % dd bs=16M if=/dev/sda | gzip —d | nc centos2.acmelabs.spb.ru 19000
Вместоgzip’а можно использовать командуbzip2или дажеlzmaс теми же ключами. Простоgzipхоть и сжимает похуже, но зато работает намного быстрее. - А вариант со сжатием можно ещё улучшить добавив визуализацию:
12(target) root@sysresccd /root % nc —l —p 19000 | gzip —d | pv | dd bs=16M of=/dev/sda conv=notrunc,noerror(source) root@sysresccd /root % pv /dev/sda | gzip —c | nc centos2.acmelabs.spb.ru 19000
Теперь, во время копирования содержимого диска будет не просто чёрный экран, а вполне себе информативное сообщение:
14.54GiB 0:01:50 [ 124MiB/s] [42.2MiB/s] [==========> ] 28% ETA 0:04:37 - Но и предыдущий вариант можно немного видоизменить, добавив ещё больше красоты:
12(target) root@sysresccd /root % nc —l —p 19000 | gzip —d | pv | dd bs=16M of=/dev/sda conv=notrunc,noerror(source) root@sysresccd /root % (pv —n /dev/sda | gzip —c | nc centos2.acmelabs.spb.ru 19000) 2>&1 | dialog —gauge «Выполнение команды dd…» 7 65
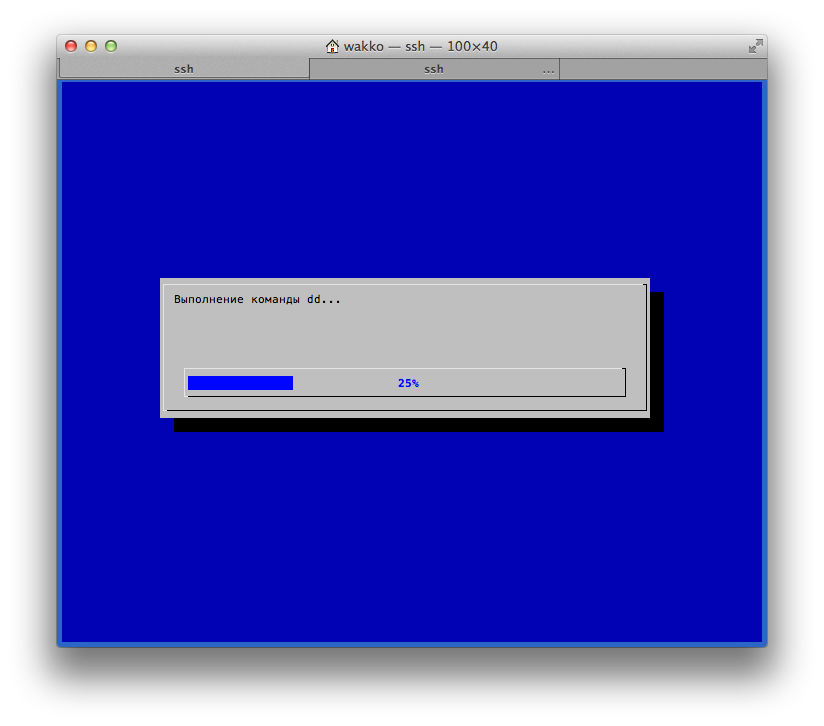
Единственную проблему заметил с этим
pv, если не заворачивать пайп сddнаpv, а напрямую читать диск с помощьюpv, то в конце, когда всё прочитано –pvне завершается и приходится нажиматьCtrl+C. Но лучше подождать, пока в консоли реципиента не появится сообщение о том что всё прочитано и записано:116GiB 0:11:34 [23.6MiB/s] [23.6MiB/s] [ <=> ] - Update: 2016-01-01: В
ddначиная сCentOS 7.2появился новый ключstatus=progress, если его добавить к команде, то в консоли ежесекундно будет отображаться статус, аналогичный тому что появляется в самом конце выполнения команды. - После копирования можно проверить, одинаково ли скопировалось командами:
123456(source) root@sysresccd /root % pv /dev/sda | md5sum16GiB 0:00:42 [ 386MiB/s] [====================================================>] 100%aca0688428a260955bd026da124017e8 —(target) root@sysresccd /root % pv /dev/sda | md5sum16GiB 0:05:39 [48.3MiB/s] [====================================================>] 100%aca0688428a260955bd026da124017e8 —
Как видим, в моём случае контрольная сумма совпадает, значит содержимое дисков идентично.
После этой процедуры на реципиенте можно уже загружаться с записанного диска.
Увеличение раздела и LVM’а
Итак, допустим Вы перенесли содержимое одного диска меньшего размера на другой диск большего размера. Так как при побайтовом копировании используя команду dd копируется и таблица разделов, у нас может получиться примерно так:
|
1
2
3
4
5
6
7
8
9
10
|
# parted /dev/vda print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 68.7GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 538MB 537MB primary xfs boot
2 538MB 54.2GB 53.7GB primary lvm
|
Как мы видим, у нас размер диска 68.7GB, а 2-й раздел с LVM’ом заканчивается где-то на отметке 54.2GB. Т.е. 14,5 гигабайт у нас осталось неразмеченным. Попробуем исправить эту ситуацию.
Существует два варианта увеличения раздела.
Вариант с удалением существующего и созданием на его месте нового раздела с другим размером
Для начала запустим parted, и сделаем так, чтобы он оперировал секторами:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# parted /dev/vda
GNU Parted 3.1
Using /dev/vda
Welcome to GNU Parted! Type ‘help’ to view a list of commands.
(parted) unit s
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 134217728s
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 2048s 1050623s 1048576s primary xfs boot
2 1050624s 105922559s 104871936s primary lvm
|
Обязательно запишите свои значения номеров начального (Start) и конечного (End) секторов разделов. Это пригодится в дальнейшем.
Теперь удалим существующий 2-й раздел:
|
1
2
3
4
5
6
7
8
9
10
|
(parted) rm 2
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 134217728s
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 2048s 1050623s 1048576s primary xfs boot
|
Если Вы пытаетесь пересоздавать разделы по-живому, то скорее всего Вы получите такую ошибку:
|
1
2
3
|
Error: Partition(s) 2 on /dev/vda have been written, but we have been unable to inform the kernel of the change, probably because it/they are in use. As a result,
the old partition(s) will remain in use. You should reboot now before making further changes.
Ignore/Cancel? I
|
Здесь можно ответить «Ignore», но после пересоздания разделов – лучше перезагрузить сервер.
И на месте удалённого раздела создадим новый:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
(parted) mkpart primary 1050624s —1s
(parted) set 2 lvm on
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 134217728s
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 2048s 1050623s 1048576s primary xfs boot
2 1050624s 134217727s 133167104s primary lvm
|
При создании нового раздела, в качестве номера начального сектора раздела указываем то же значение, что и было у того раздела, что мы удалили, а в качестве номера конечного сектора раздела указываем -1s, что означает последний сектор. Т.е. создаём раздел максимального размера. А команда «set 2 lvm on» означает что для раздела #2 указываем его предназначение – LVM.
После создания нового раздела – можно выйти из parted’а:
|
1
|
(parted) quit
|
Вариант с увеличением раздела без удаления
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# parted /dev/vda
GNU Parted 3.1
Using /dev/vda
Welcome to GNU Parted! Type ‘help’ to view a list of commands.
(parted) unit s
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vda: 134217728s
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 2048s 1050623s 1048576s primary xfs boot
2 1050624s 105922559s 104871936s primary lvm
(parted) resize 2 1050624s —1s
(parted) quit
|
Но есть проблема. Команду resize и resizepart убрали из последних версий parted’а, по крайней мере в CentOS 7 этих команд в parted’е нет. Поэтому лучше пользоваться первым вариантом с удалением и пересозданием раздела.
После того как раздел увеличили, необходимо увеличить физический том LVM на этом разделе. Сначала выполняем команду:
|
1
2
3
|
# pvscan
PV /dev/vda2 VG vg_acmenet lvm2 [50.00 GiB / 4.00 MiB free]
Total: 1 [50.00 GiB] / in use: 1 [50.00 GiB] / in no VG: 0 [0 ]
|
Как видим, размер нашего LVM’а 50 GiB. Для увеличения физического тома LVM выполним следующую команду:
|
1
2
3
4
5
6
|
# pvresize /dev/vda2
Physical volume «/dev/vda2» changed
1 physical volume(s) resized / 0 physical volume(s) not resized
# pvscan
PV /dev/vda2 VG vg_acmenet lvm2 [50.00 GiB / 4.00 MiB free]
Total: 1 [50.00 GiB] / in use: 1 [50.00 GiB] / in no VG: 0 [0 ]
|
Эта команда означает что нужно расширить физический том LVM на всю величину раздела. Если в результате мы видим что размер LVM увеличился – значит всё хорошо, если же нет – значит нужно сначала перезагрузить сервер, а потом повторить выполнение этих двух команд.
Пробуем после перезагрузки:
|
1
2
3
4
5
6
|
# pvresize /dev/vda2
Physical volume «/dev/vda2» changed
1 physical volume(s) resized / 0 physical volume(s) not resized
# pvscan
PV /dev/vda2 VG vg_acmenet lvm2 [63.50 GiB / 13.50 GiB free]
Total: 1 [63.50 GiB] / in use: 1 [63.50 GiB] / in no VG: 0 [0 ]
|
Как видим, после перезагрузки всё получилось так как и планировали. Размер нашего LVM’а увеличился.
Вообще лучше всего изменять разделы и файловые системы загрузившись в
SystemRescueCD, а не напрямую изнутри.
hitmany
20.03.2016 - 09:44
Последнее с изменением размера не понятно, первый раз перенес ввожу parted print важный раздел весит 29 mb, ждал перенос полчаса
hit man
20.03.2016 - 09:47
Первый раз почему то ввожу parted print важный раздел весит 29 мб,
Щас второй раз пробую
Пункт про изменение размера диска не понятен, что значит удаление? мне нужно перенос а не с нуля ставить)
Использовал это
(target) root@sysresccd /root % nc -l -p 19000 | pv | dd bs=16M of=/dev/sda conv=notrunc,noerror
(source) root@sysresccd /root % pv /dev/sda | nc centos2.acmelabs.spb.ru 19000
Я без сжатия начал, потому проц тупит